用SVM算法思想设计企业架构从根源解决数据治理问题
问题背景
之前有段时间我非常困惑,企业业务是清晰,数据是清晰的,为什么就是不能切分出业务和数据的合理映射,反而在业务系统中,DDD实践就很好的解决了这个问题,最近我在工作的时候,想到了SVM,想到了SVM中的核函数。
世界上本来没有两个完全一样的物体,对于所有的两个物体,我们可以通过增加维度来让他们最终有所区别,比如说两本书,从(颜色,内容)两个维度来说,可能是一样的,我们可以加上作者这个维度,实在不行我们还可以加入页码,可以加入拥有者,可以加入购买地点,可以加入笔记内容等等。当维度增加到无限维的时候,一定可以让任意的两个物体可分了. |
这里难的地方在于已知纬度不足的前提下,如何自动生成一些的新维度,并且要和旧的纬度进行关联,让这些数据可以分开,这个过程就是SVM的核函数干的事,一下子我发现这个问题,和曾经苦苦寻找的如何在业务,和数据之间找一个映射切分合理的数据域,是何其相似。
- SVM愁的是如何将明明可以分开的数据,为什么分不开。
- 企业数据在数据碰到的是明明我业务都知道这是什么数据,你为什么就是拿不出来。
所以企业在做数据领域划分的时候,重点就是:如何在信息不够的前提下自动生成新的纬度,可以让各个领域不正交。
我自己觉得现在很多企业之所以会出现数据的问题,是因为虽然企业在进行架构设计的时候,虽然考虑了企业架构总体的分布式,但是可以发现在这样的架构下,虽然是分布式,但是分布式中的每一个点,实际都是端到端的完全自治的。
那么如果我们在设计架构的时候,全局可控,每一个点也能力完备,但是它需要依赖全局的能力和协调,那么自然很多问题就不会存在,但是目前大多数的自治,和全局都没有任何交互,于是导致出现很多数据的问题,只能靠后面使用治理手段来弥补这些缺陷,本质上都是因为全局设计下给予了某个点太过于端到端完备。
而治理的成本又非常高,不但不能一次性根治,还需要随着时间推进,不断投入,遗留成本越来越高,对于大多数企业来说, 数据治理都是是一个让很多企业头疼的问题,而数据治理中,主数据凸显出的问题又显得尤为明显,对于互联网类型的企业来说,本身相对来说更加注重技术。因此大部分系统在设计之初就具备更好的开放性,甚至有很多系统在设计之初便是”云原生思想”。
对很多企业来,目前最重要的其实是总结业务,然后中央集权,从而更加灵活的对各个点进行管理。
所以在主数据这个问题上便显得不那么麻烦,但是很多企业,但凡有点行业局限,都会出现局部的孤立,在使用闭源软件就会显得更加突出。
数据治理包含数据治理治理,元数据治理,主数据治理,技术上来看数据治理治理复杂的地方在于质量的度量,而主数据复杂的地方在于数据的分发,相对来说元数据倒不具备那么明显的技术难点,反而业务复杂度更高。
先以主数据治理为例,一般来说企业在进行主数据治理的时候,都会成立专门的临时团队用来基于各个业务线的数据模型,定义出何为”主数据”,紧接着需要定义出主数据的信任来源,以及如何实现数据的分布式一致。
保持分布式一致有集中管理方式和分散管理方式,集中管理方式指的是由一个中心系统统一维护主数据的变更,各个业务系统各自从集中管理的地方进行同步,为了保持性能,一般各个业务系统会在本地生成一份镜像,然后自己基于业务诉求决定镜像的更新机制。
集中管理麻烦的地方在于每一次的更新修改,都需要从中心库去实现,然后再同步到本地,这样增加了网络传输的问题,其次如果涉及到需要在本地进行join的场景,就只能做本地镜像。
另一种是本地各自维护,统一上报,也就是主数据的变更可以发生在任何系统,但是需要上报中心,由中心决定是否接受以及如何通知其他系统发生了更新。这种方式带来的好处是不存在本地关联的问题,同时引入的问题是如何让其他系统感知数据变化和解决数据冲突的问题。
从感觉上来说,好像也就是无论使用哪种方式来做主数据治理,貌似都会存在一些问题,这么来看,应该是抽象还不够,也就是架构师视野狭隘了。
那么想象下svm解决非线性可分的方案?
借鉴SVM高纬抽象
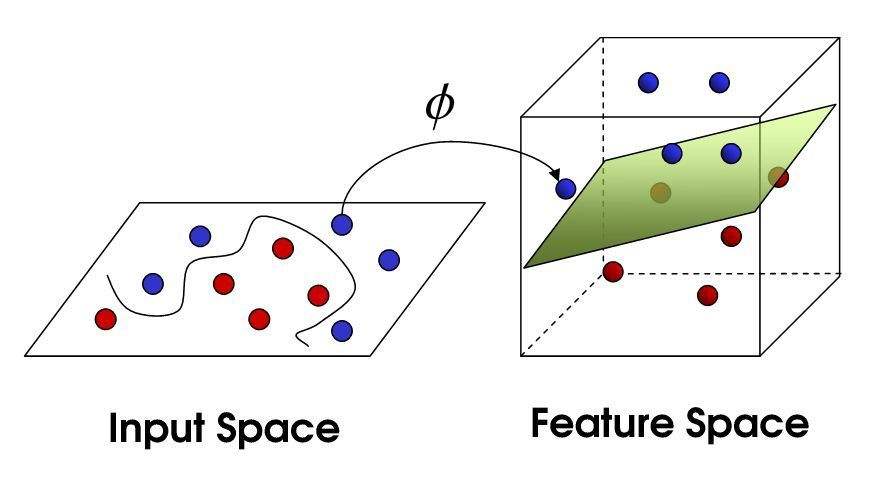
当数据在当前纬度下出现线性不可分,那么就使用一个高阶函数,将数据投射到更高维护,形成一个超平面,再来看是否可分,如果不行继续高纬抽象,因为超平面有无数个,总能找到一个是可分的。
也就是求解能够正确划分训练数据集并且几何间隔最大的分离超平面,对于线性可分的数据集来说,这样的超平面有无穷多个(即感知机),但是几何间隔最大的分离超平面却是唯一的。
可以发现SVM要解决的问题,和企业架构在做数据上碰到的问题是不是非常类似?
- SVM是寻找新纬度,把数据分开。
- 企业数据找到新的边界,把数据依托业务的映射关系,分开。
SVM将数据的纬度进行提升,找到一个超平面,就能把数据分开了,如何提升纬度找到超平面,这是SVM的核函数做的,将企业数据分开,这是企业数据治理做的,但是目前企业的数据治理并不好,问题很多,本质上就是架构视角不对,再想想SVM。
回到主数据这个问题上,既然在业务系统的架构约束下解决不了这个问题,那么就放大架构,看下在整个企业数据流的概念是否能够解决这问题?不断的提升数据架构的视野纬度,如果单系统不行就跨部分,跨部分不行就到公司,公司不行就到行业,总能找到一个纬度是可分的。
这是不是和SVM的核函数的思路非常类似了?
设计一下架构
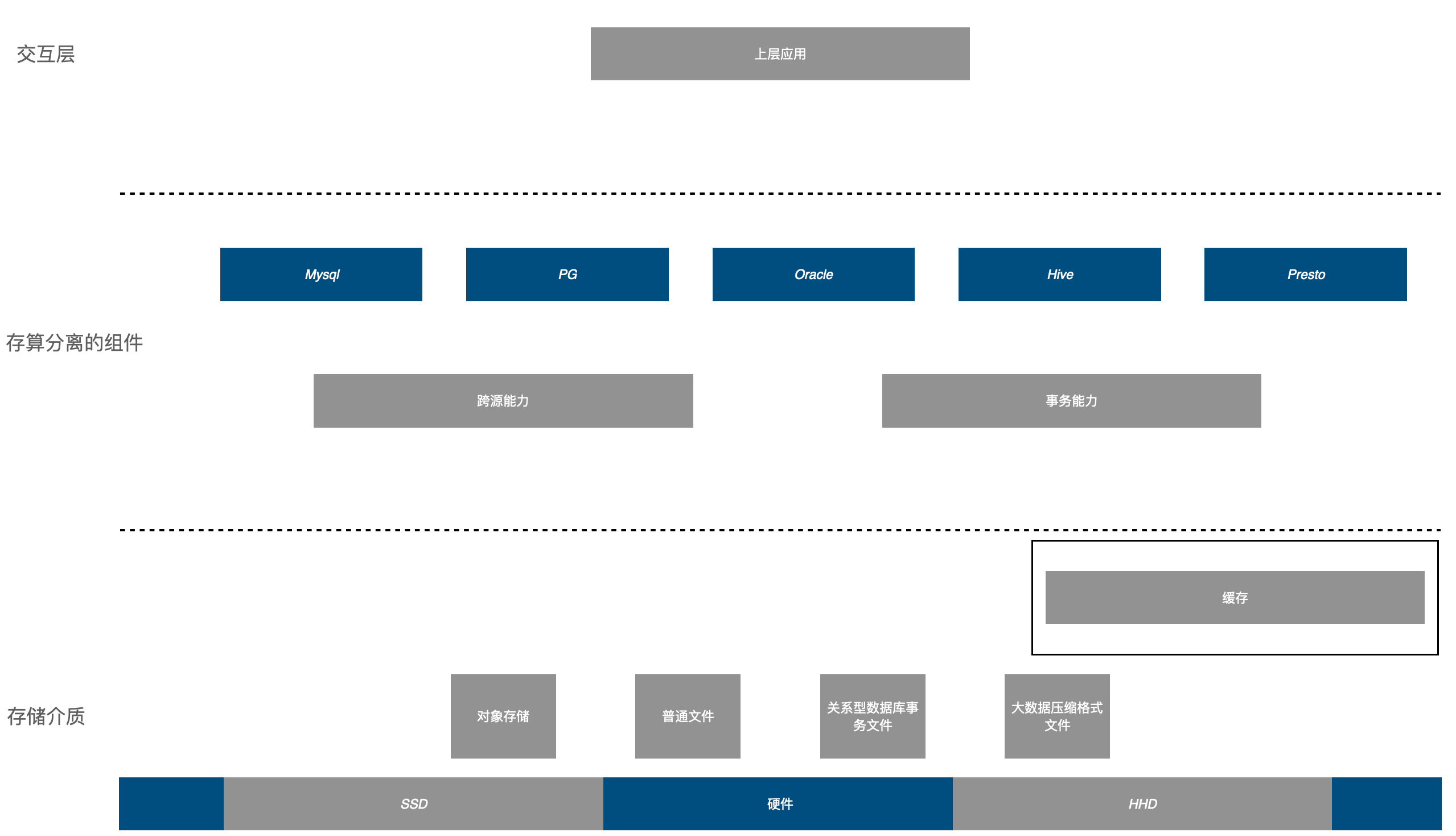
那么如上图所示,我们这么看来,企业底层有一个大的数据存储介质,无论是什么数据都存在这里,这个介质上层如果是关系型数据库来接入的,那么他支撑的就是业务系统,实现低延迟,强事务,高并发的能力,如果对接的是大数据组件,那么支撑的就是数据挖掘,实现的就是高吞吐量,分布式计算的能力。
之所以这样可以解决问题,是因为我们发现在以单个系统为视角无法解决问题,就提升到部门,再不行到业务线,再不行就到企业,不断提升视野,总能找到一个纬度会发现,这些问题和治理是根本不存在的,这就是用SVM的思想来设计你的企业架构。
整个架构从企业的视角又变成了三层架构:底层的存储介质层,中间的计算引擎层,和上层的交互层。
只是说这里面的每一层都是逻辑架构,由无数的组件合成,但是对外可能提供的是一个接口,例如存储介质层可能原始的文件都存储在对象存储上,但是基于引擎需要它会”自动挪数据”,挪到ssd等介质上,这一切对引擎都是透明的,就像aws的s3和redshif,但是要做的比它更彻底。
中间的计算引擎是彻底的存算分离完全解耦,包括mysql这一类关系型数据库也要存储计算解耦,这里可能有人会觉得解耦后,必然会有数据suffle,那么不就性能跟不上了,当然不是这样,目前大部分系统都不完全依赖数据库本身的物理介质的IO来决定自身的并发和性能,这类问题都可以靠底层存储介质的”自动数据挪动”,缓存以及和引擎自身的缓存等机制结合,彻底解决这个问题。
交互层就是流程和用户交互相关的工作,粗暴理解就是前端。
这样来看的话,主数据的问题就非常好解决了,只需卡住底层落盘的通道,对某些数据提供只读接口,某些数据就是主数据,那么这样的话主数据就彻底解决了,也就是从映射来说大家看到的都是表,但是某些表对某些系统是只读的。
另外由于数据都是存储在底层介质下,所以数据自然是同步和一致的。而如何把企业的业务抽象成这样的三层,这就是企业的核函数,需要精心设计的,就是这部分工作。
那么在这样的思路设计下,需要解决的问题是:
- 存储层面的缓存和智能的数据优化。
- 引擎层面的跨源,比如数据可能在s3和本地文件等不同的介质上。
- 事务型的介质如何存算分离,并且依旧需要保留事务机制。
- 如何实现同源下读写分离的底层存储介质
可以看到这样的思路下,其实就不需要所谓的数据变更通知了,毕竟都是逻辑一体,不存在通知,而引擎组件的特性也很明显,都是事务极致或者批处理极致的方向发展,也就是虽然存算分离了,但是每一个组件的特点也非常明显,不存在可以相互替换和大而统的组件。
张小龙曾经设计了微信后,马化腾问他你怎么解决垃圾搔扰信息的问题,张小龙说这样的设计天生就不存在啊,因为微信基于订阅和免打扰的模式,也就是凡是过来的消息,都是对用户有用的,从天然设计就解决了垃圾信息的问题。同样的逻辑如果以企业的视角来看局部面临的这些数据一致性的问题,将它抽象到三层架构后,天然就不存在数据一致性的问题了,根本不用治理,数据引擎支持跨源分析,因此不用关心数据在哪,其次介质支持数据移动,只有一个介质,自然不存在多写的问题。
于是可以发现,这样的设计下,无论是主数据和元数据,可以从根本上杜绝数据在局部出现的治理问题,背后的思路就非常企业云原生了。
- 当业务系统发展的时候,以业务系统的技术架构为主,以企业组织职能部门进行配合。
- 当数据架构发展的时候,以数据架构和业务架构打通为主,以企业人才梯队结构进行配合。
- 当业务架构与系统架构冲突带来较大的治理成本的时候,以企业视角切入,进行架构设计,业务系统和数据业务进行配合。
由此可见很历史确实是螺旋状的,天下也是分久必合,合久必分。
扫码手机观看或分享: