如何为智能应用构建长期记忆
之前我写的一篇文章中我与AI深度Pair这个把月提到大模型目前在工程视角下的问题,比如没有记忆能力,导致脱离上下文的历史记录窗口,智商就回到一个固定时间点的快照。
比如,在一个长达一小时的视频中:第 5 分钟,一个「穿蓝色衬衫的男人」出现;第 25 分钟,一个「戴着眼镜的男人」发表了讲话。对于人类观察者而言,很容易判断他们是同一个人。 |
但对于 AI 系统,这却是一个难题,因为AI自身是没有对自己已经处理过的知识信息进行提取处理的流程,因此AI是一个健忘的,没有记忆的人,它的记忆力始终停留在模型厂商训练它所使用的知识的阶段,无法进阶到使用者投喂给它的知识的这个阶段。
这个问题非常影响实际的质量,如果不解决这个问题,会导致智能应用最佳效果是上线那一刻,随着使用的时间增加,质量会越来越差,除非投入更庞大的维护成本,前几天字节出了M3 agent,刚好解决的是类似的问题:
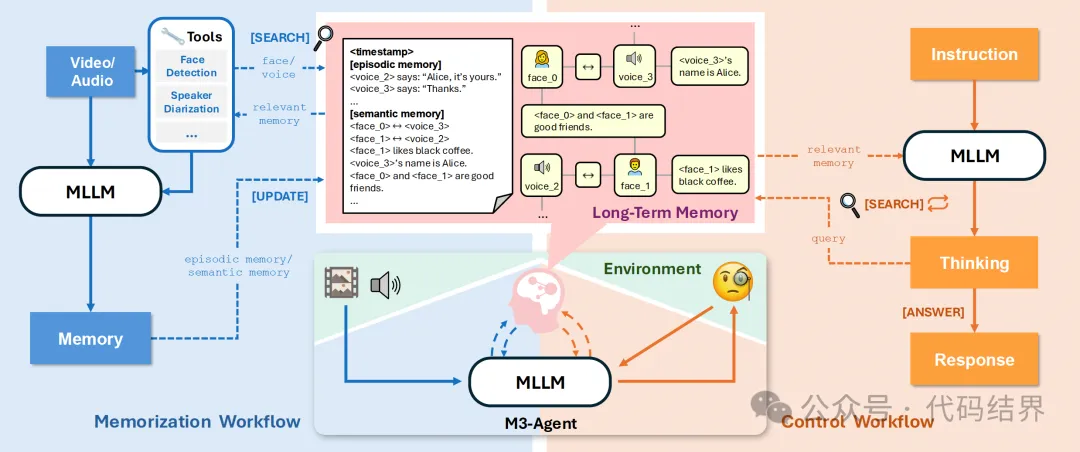
M3 Agent的解决思路是由一个多模态大语言模型(MLLM)和一个外部的长期记忆模块构成。其运作通过两个并行且持续进行的过程实现:记忆化 (Memorization) 和 控制 (Control) 。
简单来说其实就是把知识提取出来后,从原始的数据中进行分层,再由控制器提供检索,而提取后又基于实体信息构建了一个知识网,而这和我正在尝试在外围构建一个服务,作为另一种类型的知识库,用于大模型自身的记忆模块的思路几乎一致。只不过M3 Agent目前是在多模态下做的尝试,而我则想构建一个更加通用的体系可以适应于不同的数据集,在大模型的问答之上,构建一个知识流转模块。
从长远来说,这个能力我认为大概率会被模型厂商给实现掉,因为如果模型在落地过程中如果不能解决记忆的问题,那么意味着每一个智能应用随着时间的推移,越使用维护成本会越高,这不太符合发展的规律。
在我看来,大模型自身的记忆能力和外围知识库的关系,并不是单纯的存储类型不同。
当我们在做存储系统,比如存算分离的情况下,通常会有一个本地缓存,将远端的数据缓存在本地,当查询的时候直接从本地读取则会大大提升加载速度。
这种情况下要求本地缓存和远端数据具有严格的一致性,然而在大模型和知识库之间,并非这样的关系,如果完全依靠大模型自身的能力去问答,显然会缺失很多内部的数据知识,导致答案质量不符合预期,如果外挂知识库,随着时间的推移,知识库会越来越庞大,必然导致检索时间增强,上下文内容过大,出现无法回答问题的情况。
为了解决这个问题,会做很多额外操作,比如知识的压缩,历史记录的对齐,甚至做部分微调来降低知识库的内容。
可以发现知识库的企业自有知识和大模型自身的知识之间并不是完全的一一对等,那么什么应该放在知识库,什么应该去微调,什么又是大模型的记忆数据,就必须定义的清清楚楚。
我认为从用户输入问题开始到模型产生输出,在这个过程中涉及到的数据的流转,经历的是知识的加工过程,而非数据存储的转移,应该遵循漏斗筛选的去转移知识。
也就是需要在用户的聊天记录+外挂知识库+大模型自身内置的知识中间形成一个流转和淘汰的机制。
而要形成这个机制,首先就需要对知识进行分层,比如最简单的知识分层:
- 用于存储历史记录的知识库。
- 用于存储领域知识的知识库。
- 用于存储问答所需要的知识的知识库。
- 用于存储微调数据的知识库。
在我开始设计UniverAI这个平台UniverAI一款企业AI员工协作平台的知识库的时候,我就首先考虑了领域知识和业务的数据知识。
在这多层知识库之间还需要有一个流动机制,当知识从上层流转至下层后,还需要进行清理,类似层级缓存的淘汰机制一样。
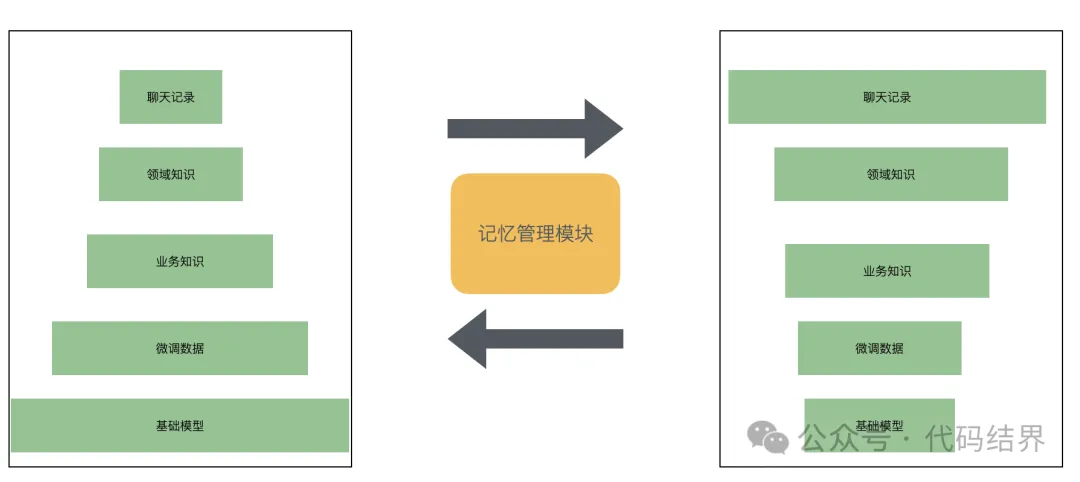
一个合理的,健康的,质量还不错的智能应用,应该是左边的这样一个知识分布,但是随着使用时间的增加,知识的变多,逐步会变成后边这种头头重脚轻的结构,导致大量的信息堆砌在了前端,需要借助庞大的上下文才能获得较好的质量,甚至都不能获得较好的质量,这时候整个应用会出现使用上体验变慢,知识维护麻烦,问答幻觉非常严重,问答质量非常差的情况。
因此需要一直机制,将起从后边拉回左边的结构,回归一个高质量应用的本体,而这个拉回的动作,实际上就是让上层知识流动到下层进行固化,因为固化了,自然就记忆到了下层,从而能解决大模型本身的记忆的问题。
而这个记忆管理模块,就需要负责全方位观察用户的输入和产生问题的答案的信息来源,从中整理出整个数据流向,因为这个模块不单要做知识的流转,还需要做知识的加工淘汰,就像人的记忆一样,有些错误的无用的信息,是没有必要保留的,需要适当的遗忘。
关于这个记忆模块的设计,后面的篇章再逐步展开。。。
扫码手机观看或分享: