聊一聊机器学习在干什么?
摘要
机器学习是让计算机从较多的数据中提取出有用的信息,最后拥有决策判别的能力,那么在研究这件事之前,先放一张图片来做一个总结:
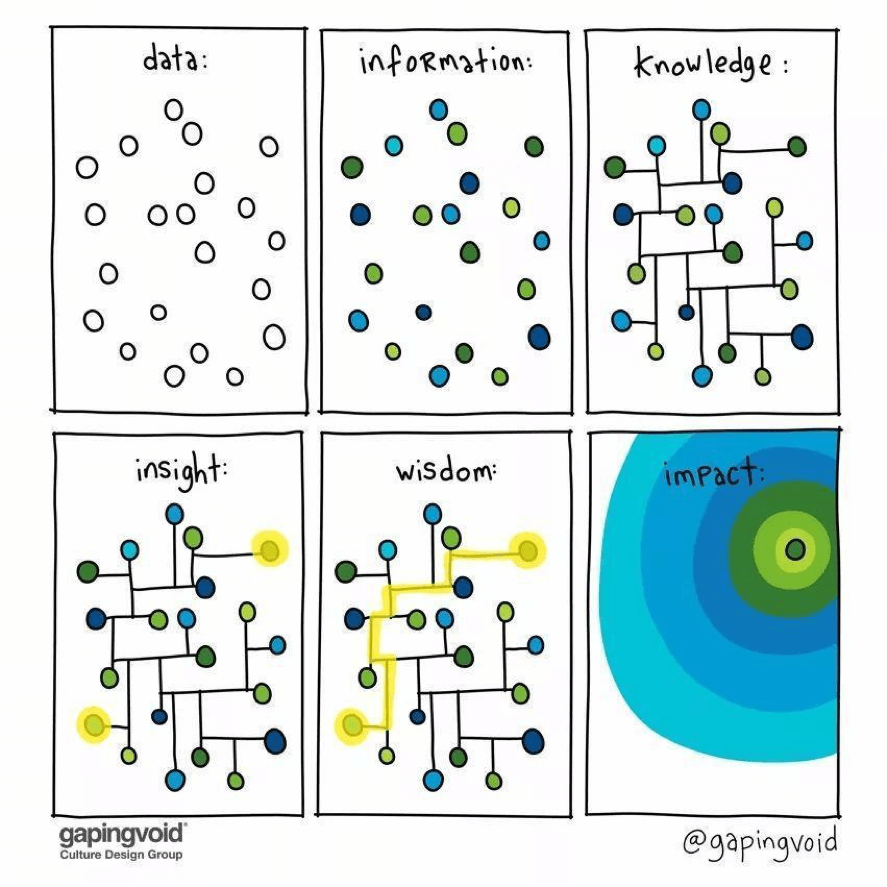
当我第一次看到这个图的时候,就被吸引了,因为这么简单的6个小框框就诠释出了数据分析,机器学习,以及知识和信息的本质,那就是:
- 数据经过处理和加工,变成了信息。
- 信息之间产生了联系,形成了知识。
- 通过现有知识,发现了一些知识之间的新关系,于是形成了洞见。
- 把一系列洞见串联起来,形成了智慧。
- 向外传播智慧,形成了影响力。
要知道,现在大家所使用的一切数据分析技术,无论是大数据还是机器学习,都是在实现这里面的某一个环节,而最终的环节,就是机器学习最终的目标,我们不是希望机器学习学到知识,这是一个手段,我们希望计算机可以具有智慧,而智慧又是无法量化的,似乎目前只能从大量的知识中去学习,至少人类就是这样过来的。
机器学习和硬件
机器学习的硬件设施是机器,没有机器一切就白搭了,机器就等于是人体,但是照着这个逻辑不太对啊,毕竟机器的构成和人可是差着八杆子打不着的距离。人脑是有非常多的细胞,各种骨干。而计算机,基本只有基本几块CPU,几块磁盘,一堆电路板。
实际上在我看来,当前大规模在使用的机器,其天生并不是为机器学习所准备,因为目前的计算机是为了解决逻辑规则的问题,也就是用纸袋穿孔可以表达的内容。那么如何让计算机拥有智慧,像人一样思考?首先我们想想,为什么机器学习总要强调人呢?目前的生物里面,大概只有人类会认为自己拥有智慧吧。所以从这个角度来说我们希望机器像人一样拥有智慧,然后去为我们服务,去解决问题。
可惜目前的机器在硬件层面都不满足基本的人类身体结构,比如人类的大脑有无数的脑细胞,有非常多的神经元,这些东西对人类拥有智慧和具有思考能力起了非常大的作用,那么计算机没有这些东西,该怎么办呢?
很简单的一个办法就是模拟,所以目前所有的深度神经网络都是利用计算机的计算能力来模拟出成千上万神经元来达到仿真的效果。然后再用模拟出来的这个神经网络,去解决真正业务的问题。所以相比一般的程序,深度神经网络多了一个仿真再处理的过程,等于是开了虚拟机再运行程序。
有了以上前提,我们不得不承认一个现实,那就是深度学习比一般的程序运行需要更高的配置,更消耗资源。同时为什么传统机器学习大家会觉得快呢?是因为传统机器学习基于统计学成功的把思考的这个问题转换为可以通过规则和逻辑来表达的方式,所以让计算机就像处理一般的程序一样,无需经过仿真环节,直接动用逻辑计算能力。
以上信息可以帮助我们在进行技术选型,以及硬件采购的时候合理的评估哪种方式是更合适于自身的。
从硬件本身的发展来说,设想一下如果计算机的硬件组成部分就是无数个神经元,未来我们可以在京东上购买一个神经元添加到计算机里面让计算机更聪明,该有多好。目前的各种AI芯片,也是尽可能的在效率方面更好的提升仿真性能。有可能未来某一天我们购买服务器的时候,组装的就不是硬件服务器了,而是组装的一个神经网络了。
机器学习学什么?
有了硬件的支撑,我们要让计算机具备智慧,那么就意味着计算机需要思考,可以怎么思考呢,前提是它总得懂点什么吧?可是懂点什么好呢?规则最好使,因为早期大家认为人就是通过规则来认识这个世界的,于是我们将规则录入到计算机中,比如:(天上有乌云,天气闷热)-> 将要下雨。这样的话计算机就可以根据天气状况来判断是否会下雨。那么怎么产生这样的规则,手动录入似乎是一个选择,可是工作量也太大了。
是否有更好的办法呢?由数学闪亮登场,基于统计学的机器学习,可以人为去调整特征来分析对结果的影响,合理的提取出哪些特征可以用来组成一个集合,作为机器判断的依据。并且将这种知识用规则去描述,让计算机依托规则做决策,拥有智慧,速度也非常快,这一切工作的非常好。
直到某一天,大家发现,不对啊,人不是通过规则来认知这个世界的,比如说人能够识别出这是狗,并不是因为它符合某种可以被穷举的规则,就像我们认识某个人,哪怕他只漏出半边脸,我们依旧可以认识他一样。这不是规则,这是某种不可被穷举同时也不可被描述的模式。
另外人能够灵活的思考和做事并且实时对问题作出响应都是在不停的预测和处理异常。比如下班回家掏出钥匙开门,是因为预测了门会在那个位置,所以前面会先掏钥匙,这一切都是正常运行,如果某一天掏了钥匙发现门不见了,这时候人会打乱之前的逻辑,就是因为实际发生和预测不匹配。人无时无刻不处在预测->验证->再学习的过程,而不是靠规则生活。
那么机器学习,要学习的当然是模式,而不是一系列可以用来穷举的规则,于是深度学习出现了,深度学习可以通过某种不可描述不可解释的行为让计算机更加神秘。通过深度学习,我们可以学到经验和知识。
机器学习怎么学?
既然我们知道了机器学习学习的是知识和经验,那么知识和经验是什么?怎么学习?对于傻的不能再傻的计算机来说,它只能识别0和1的数字,那么怎么让它知道:
我路过了一个非常美丽的臭水沟。 |
这三句话其实讲的是同一个意思?简单,用一种方式将这个文字变成一串0101010101的数字就好。什么方式呢?可以这样:
我/ 路过了/ 一个/ 非常美丽/ 的/ 臭水沟。 |
然后做词干处理,再做停词过滤等等操作,最后使用one hot编码词语再把整个句子串起来。
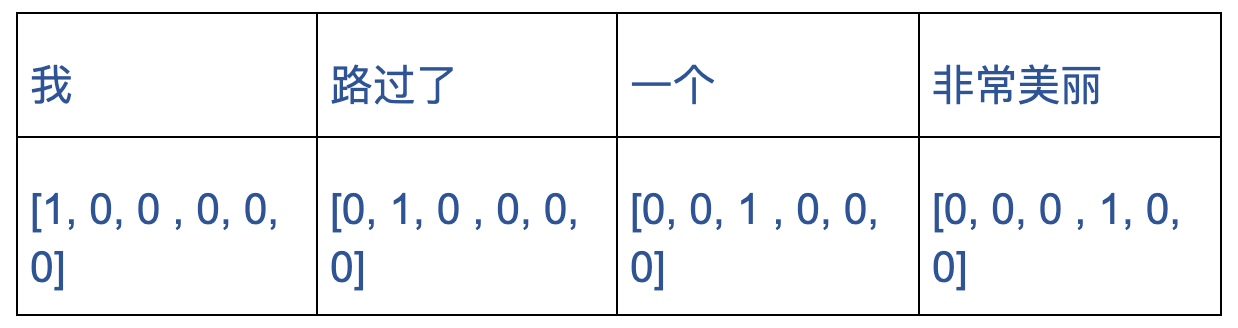
这样每一个句子都可以得到类似这样的一堆向量,有了这一堆向量怎么去判断他们到底是否一样呢?再把我们中学学过的数学知识余弦夹角公式一放:
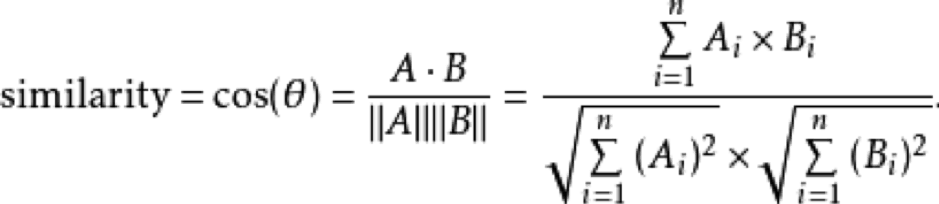
通过余弦夹角就可以判断两个向量的相似度:
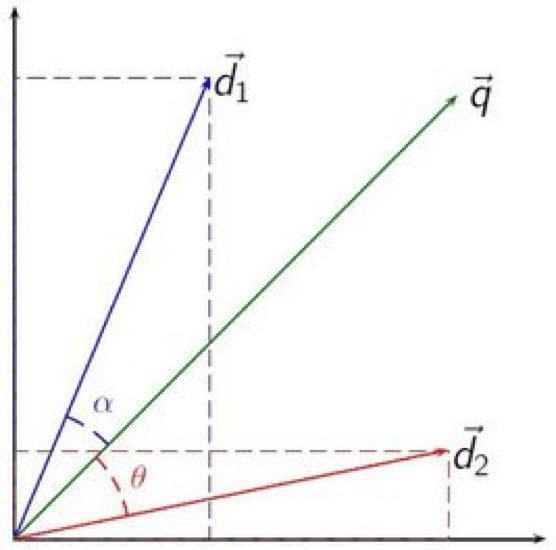
看起来好像计算机很厉害了,可以知道两个句子的含义是否一样了,但是仔细品味还是会发现上面这种做法存在的问题:
- 对于向量化的规则,依旧使用规则制。
- 中华文明博大精深,照上面的算法计算机再厉害也扛不住巨大的向量化后的结果。
- 中文博大精深,一些隐喻、上下文关系在上面根本体现不出来。
也就是说,上面的做法只能让计算机懂得字面意思,完全无法理解句子之间的隐喻以及词语之间的相关性等等含义。比如上面的做法完全无法知道:“宽敞”和“宽阔”是近义词。
所以我们需要一种方法让计算机可以在文本里面学的更多的隐含意思,先甩出两张图:
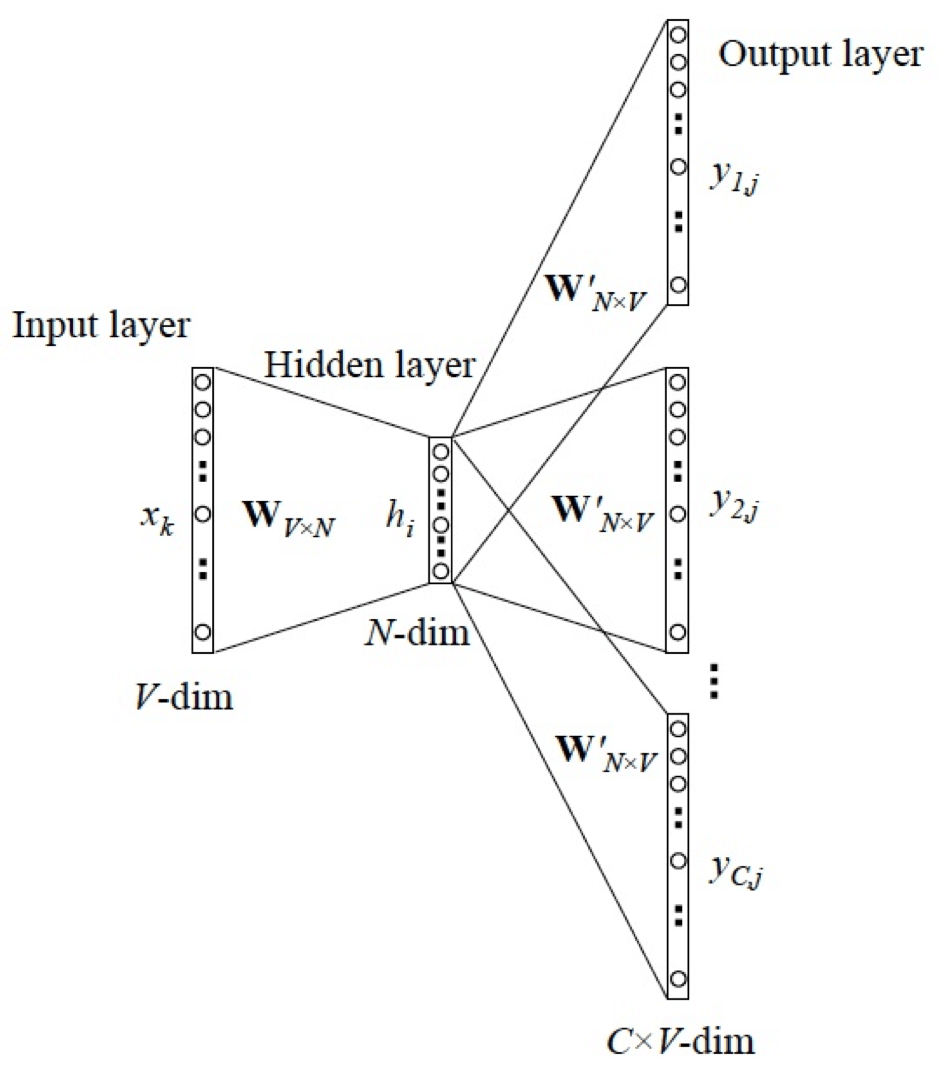
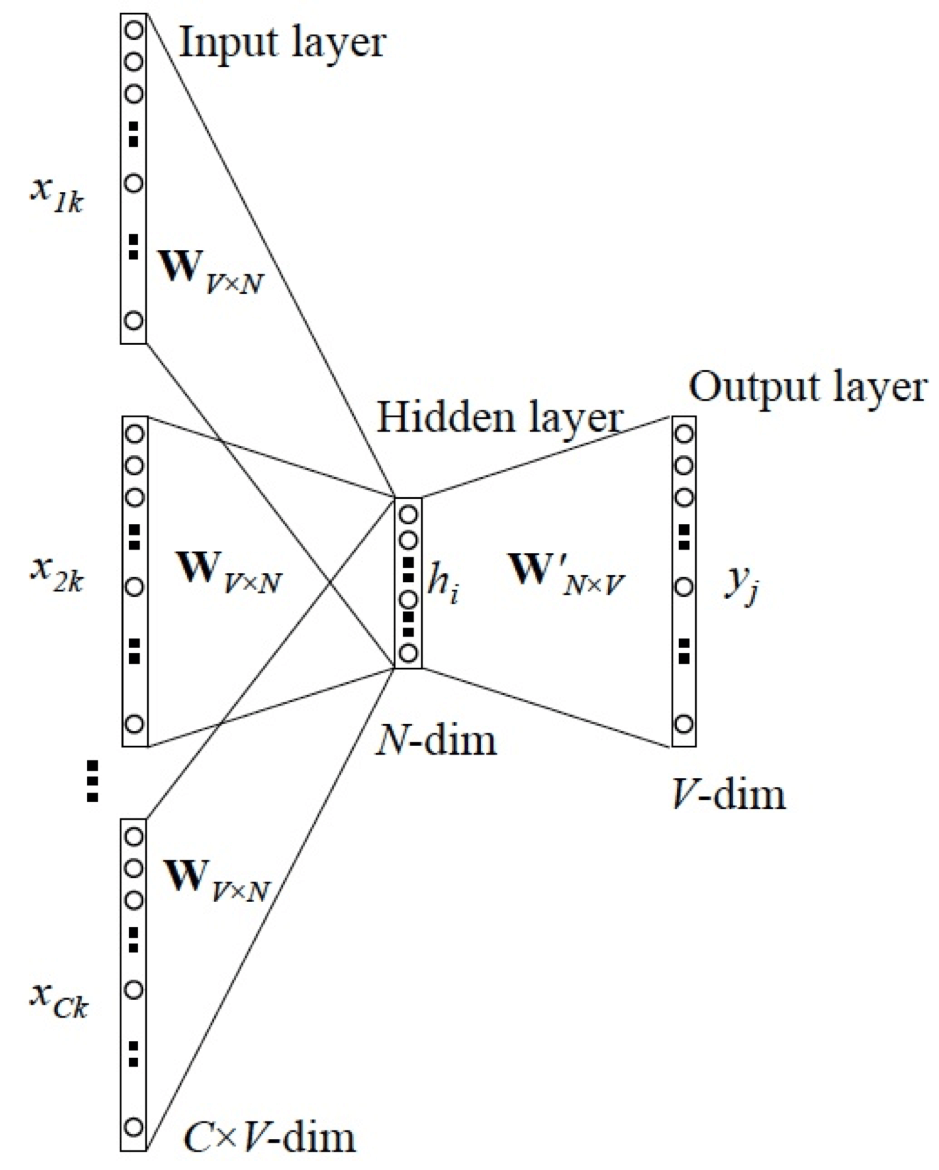
看起来这个图毕竟复杂的样子,实际上这就是Word2Vec的Skip-gram和CBOW的算法,它解决了什么问题呢?比如有以下句子:
我长得非常帅,大家都喜欢我。 |
那么我们可以找出一个函数让:
f(我) = [非常,帅,大家,喜欢] |
这个时候就可以知道:我=张三,近义词或者推理逻辑就出来了,唯一巧妙的是word2vec并不是需要这个厉害的f()函数,而是仅仅使用了中间的向量化的临时结果。
所以机器学习到底是怎么学的呢,其实就是将人类知识录入,转为向量后,利用数学规律,去发现数学的相关,再用业务视角去解释这些相关性,如果是已经存在的关联,计算机就可以做决策,如果是不存在的相关性,我们叫它创新。
如何合理使用机器学习这些技术到工程中?
那么,机器学习既能学习,又知道怎么学,我们作为一介码农或者一个企业,该如何应用它?
首先我们不要对机器学习报以太大的通用解决方案的期望,也就是说不会有一种机器学习方法可以通用解决所有问题。一个完美到足以涵盖一切可能输入分布的学习理论,它也必定平凡到无法直接处理稍微有针对性的问题(敲黑板,要考)。
其次也不要指望可以用较低的成本瞬间获得机器学习带来的福利。当我们利用它的时候就需要明白它的合适的场景和合理的使用方法。

以上的流程是常规的数据探索常见的流程,为了支撑这个流程,我们需要一系列的基础设施支撑,例如数据的获取,存储,处理。
在不少的企业来说,对机器学习的应用场景通常会有如下几类:
利用机器学习技术解决具体的业务问题
对这类问题来说,非常聚焦,是实在的业务场景,那么操作流程应该遵从:

复杂的地方在于划分问题域,大了来说,分类和回归占据半壁江山,但是对于分类来说,如何设定特定领域下的可扩展的类别,是一门独立的复杂学科。
其次构造特征集的时候需要考虑的不单单是相关的数据采集,同时还有对应的特征关联分布等分析来确定合适的算法和效果,这样可以在前期达到事半功倍的效果。
机器学习模型更大的工作是在前半截而非训练的过程,训练过程通常等价于一般业务系统启动服务的过程,而前边的定义和划分则应该被归入机器学习story编码的一个部分。
提供机器学习现有解决方案模型的SAAS服务
对于这类服务来说,难的不是提供较多的模型服务,而是如何有针对性的提供模型服务,毕竟现有开源的服务较多,都可以开箱即用,其次如何达到较好的实效性和高并发以及持续训练。
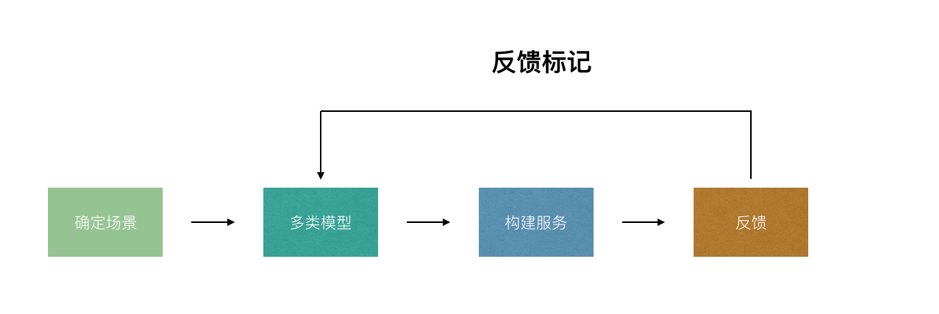
实现一个SAAS不会太难,实现一个可以根据调用和使用者逐步优化和演进的SAAS则会变得很困难。
因此在构建SAAS的时候不但需要基于可以弹性扩展的系统实现对应的服务,同时需要基于不同的库和服务来作出不一样的实现。另外在线上需要有足够多的反馈机制,用来作为核心的校验和持续训练环节。
提供机器学习构建PAAS服务
这一类的服务是大多数的企业都想实现的,大家都希望实现一个机器学习平台,可以提供标注,存储,算法实现,训练以及发布环节。让别人可以拖拉拽就写出自己的模型,发布自己的模型API。
思想没有问题,但是实际来说,大多数情况下这样的实施要么成本会变高,要么最终的价值容易体现。因为标注系统本身和ML平台并非强关联的,通常来说这类平台在企业都是具备为企业赋能的地位。
赋能指的是提高效率而非劳动力转移,因此:
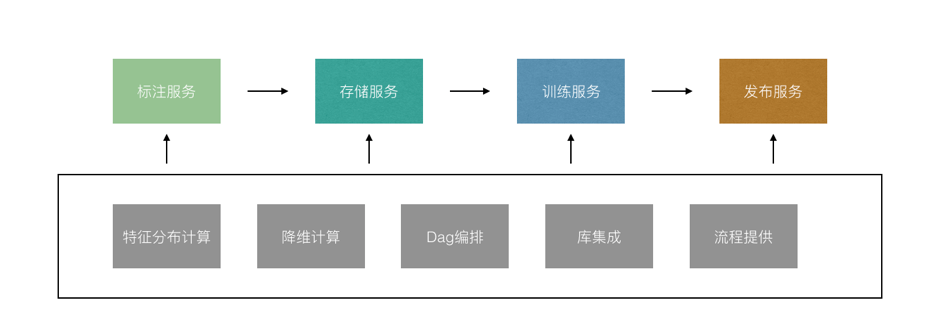
更应该关注的是特征和流程本身而非辅助的系统,所以对于这类服务来说,标注在哪,标注怎么做,不关心,也不应该关心,标注自有标注团队做。
乍一看,似乎上面讲的东西和深度学习,和神经网络没有丝毫关系,实际上知道神经网络知道卷积神经网络是如何计算,会熟练使用Tensorflow并非是一件很难的事情。真正让这个技术变成可以实实在在给人提供服务的能力,需要解决的正是周边这一系列工程化的问题。包括基本的架构,流程,扩展和团队,就像很多人都会汇编,c,c++编程语言,但不是谁都能设计出操作系统让这门语言能够产生实际的业务价值。
尾声
当我们在享受机器学习的技术带来的红利的同时,需要关注到它的缺陷以及合适的使用方案,只有较好的评估技术和业务的适应度,才能最大化的享受机器学习带来的价值和意义。
扫码手机观看或分享: