如何理解面向AI编程
技术的目的
无论编程的形式是什么,本质上还是为了解决生活中的真实问题,不外乎就是衣食住行和饱暖思淫欲的一些东西,每一次技术的迭代,所有业务都值得从头做一次,比如交通,以前是人力,然后是马车,然后是汽车,然后是飞机,需求还是把一个人从A点送到B点,但是因为技术的变化,需求的实现方式发生了变化。
战争的目的是为了资源的掠夺,而要掠夺成功就需要核心技术,掠夺成功的一方需要守住阵地,可以使用同化思想,比如引入宗教,但是这种方式的周期过长,通常需要几代人的周期,而另一种方式就是技术的降维。大到军事,小到日常,技术可以控制生活的方方面面,举个例子,Windows早期通过盗版引入迅速占领了市场,让所有人低成本使用到了高科技,然后这些国家再也没有了造出OS的能力。
最近的ChatGPT炒的火热,甚至OpenAI开放出来的API能力在收费上,还不足以缴纳电费,本质上也是同理,但是ChatGPT稍微恐怖一点的地方在于,除了科技的垄断外,未来如果有需要,它可以引导思想,逐步的通过和你对话的过程中,同化你的思想,从而达到类似宗教同化的效果。
虽然现在ChatGPT并不对国内开放,但是无论它开放与否,进入GFW不过是时间周期的问题。
机器学习的工程化
很早的时候,我就比较坚持CD4ML这个路线,当时的思路大概是这样: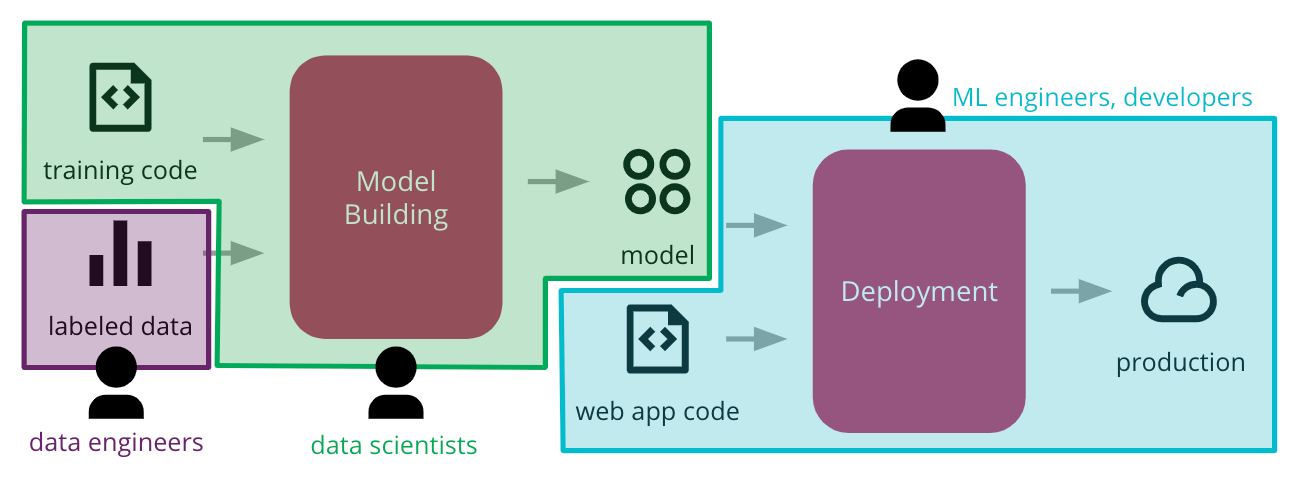
本质上是用DVC做数据的版本控制,Git做代码的版本控制,Metaflow做模型版本控制,再由调度器衔接起来,实现模型的训练和模型文件的产生,所有的模型都是标准化的例如ONNX的格式,把训练完的模型投放到文件共享平台,供其他业务的流水线去加载。
由于已经实现了模型标准化,其他业务平台只需要按照标准模型推理去加载即可,这样可以完整的把AI能力无缝的融合在整个开发流水线中,没有割裂。
曾经Thoughtworks也做过一次WorkShop 提供了一个Demo的流程,代码都还在这里:https://github.com/ThoughtWorksInc/CD4ML-Scenarios
从理论上来说,这种理论思想已经很完善和成熟了,但是工程实践上,一直没有特别完整的端到端的实现,这里面有很多原因,比如国内企业并不重视基础建设,你给老板说投资100万去抖音找个美女打个广告宣传一下他会非常开心的同意,但是你告诉他投止50万做好基础建设,这样三年后公司在技术上会有很深的壁垒,他会嗤之以鼻。老板的思想是捞一波热钱,或许他自己都没想过让业务线活过三年。
国内的企业大多都很卷,业务天天换,说的好听点是灵活,实际上还是捞热钱,至于技术,那是不存在的。
所以这一类基础建设,要在国内的企业做好,其实很难,所以大多时候,都是由国外企业做好基建,然后国内再使用。
面向AI的编程
站在软件视角,目前大部分的编程,本质上是面向库编程,因为软件已经拥有丰富的完整的生态圈,各种轮子非常完善,很多时候做业务的时候,与其说是在研究编程技术,不如说是在研究第三方库的API。
程序员本质上是利用广泛的生态圈中的基础轮子,进行业务的设计,很多时候面试的时候,提到的广度,不外乎就是知道更多的轮子,这样带来的效果就是快速的就可以用众多的第三方工具做出一套业务系统,瞬间上线,而潜移默化中,大部分企业也就丧失了底层轮子的能力,太平盛世,没有什么影响,一旦出现矛盾,别人的轮子不给你用,那么瞬间就会出现卡脖子的问题。
ChatGPT,特别是ChatGPT-4个ChatGPT的plugin出现后,市面上的评论基本上是这样的:
ChatGPT就是新时代的Iphone,而Plugin则是Appstore,众多的Plugin开发者围着ChatGPT不断的开发一个个的Plugin用来替换掉现有的APP,就像IOS生态那样。
而对于这部分开发者来说,大家更多的是面向AI编程,老实说面向AI编程是个必然的过程,之前ChatGPT出现后,很多人开始鼓吹大量失业的情况,其实对于大部分职业来说,稍安勿躁,没有那么恐怖,对于程序员来说,也没有什么大的影响,不过是逐步过渡到面向AI编程而已。
那么如何理解面向AI编程,曾经我在思考CD4ML的时候,就考虑过如何管理数据集,模型,和代码,只需要将这些东西标准化,流程化,那么就可以围绕这些内容,构建自己的业务,当模型足够多,流程足够规范,总能找到一个合适的模型使用,就像日常开发程序,总能在GitHub里面找到一个第三方工具一样。
即便有不顺手,在规范化的模型下,进行二次训练和参数微调,也能解决问题,这样的面向AI编程则基本就能稳定。
最近随着我对huggingface的深入,以及huggingface自身的日趋完善,面向AI编程这个事实基本已经有了完整的工具链支撑,huggingface首先提供了一套transformers框架,在这个框架上,做出了:
- 模型管理,包括版本。
- 集成了git能力,实现了代码管理
- 丰富的Cli,可以直接和 huggingface rep发生交互。
可以说huggingface就是新时代的maven rep和github,相信如果这个世界没有github和public maven rep,那么现在的程序员也无法做到面向库编程,也不会有那么丰富的软件生态。正因为github和public maven rep的存在,规范了代码管理和代码产物管理,让这一套流程标准化,于是这个生态就做起来了。当然maven rep更多是针对JVM语言,除了JVM语言外,其余所有语言都有自己类似的产物管理服务。
而huggingface刚好就弥补了机器学习领域的这个空白,曾经做机器学习的时候,对于如何管理数据,代码和模型,一直是非常头疼的问题,大部分都只能靠训练模型的那台机器去保存,版本化更是不复存在,如今huggingface算是比较标准化的解决这了这个问题。
当大部分人开始在huggingface上寻找合适自己的模型,大部分开源贡献者开始把自己的不同的模型,数据集贡献到huggingface后,围绕huggingface自然就会形成一套标准的交互生态,huggingface的产物是模型,于是自然大部分的工作都是在面向AI编程,而这时候大家的工作似乎也就变成了这样:
- 寻找合适的模型,使用框架加载。
- 模型不符合要求,加入自己的数据集,微调整。
- 把自己的模型再发布出去,形成开源生态。
这里有一个很关键的信息是,既然模型本质上是一个文件,为啥之前huggingface没有出现?一个原因是沉淀需要时间,其次是从transformers开始,模型的处理能力,特别是多模态就已经达到非常完善的程度了,这种情况下模型是可以独立完成业务逻辑的。
举个例子,以前做一个问答系统,需要上层提前对问题做多次处理,其中一个分支才会走到模型,而如今不需要任何分支,模型就能支持所有场景,这样的化对于编程来说,自然就由以前的以逻辑编程为主,部分逻辑套入模型,转变成模型就是逻辑,这其实就是面向AI编程的转折点。
from transformers import AutoTokenizer, AutoModel |
huggingface短短几行代码就能实现对现有模型的加载和使用,大大减少了自我实现的冗余程度,同时也仅仅需要一行代码,就能在微调的基础上完成模型的保存:
torch.save(model.state_dict(), f'epoch_{t+1}_valid_acc_{(100*valid_acc):0.1f}_model_weights.bin') |
再通过huggingface-cl则可完成和服务端的通信,用来发布自己的模型,这一套流程与日常开发的代码管理节奏几乎一致。
未来
随着ChatGPT的到来,以及几乎以指数级增加的模型效果表现来看,势必这种技术会带来全新的改变,但是这种改变并非是毁灭性的,反而ChatGPT可以让每一个人体验真正的个性化,目前ChatGPT只能让人类在精神上感受到陪伴,未来在IOT发展的势态下,ChatGPT势必从虚拟走向现实,成为日常生活中可见的物理组成部分,而不是单纯一个计算机内的软件体。
与其担忧ChatGPT的危险,倒不如思考思考如何让ChatGPT成为自己生活中的一份子。
扫码手机观看或分享: