Hadoop中put与distcp不会走Committer
Job Committer
关于什么是Job committer,这里不细说,可以参考一下这里:https://baifachuan.com/posts/93d12073.html
这里说的不走job committer是指的是不支持通过scheme的方式去产生committer,而是走了默认的hdfs的committer,这对于对象存储来说,是有影响的。
当然distcp的实现,本身逻辑还是很严谨的,例如它都提供了断点续传,distcp有个overwrite,如果这个开关没有打开,对于同一个path进行多次distcp的时候,它自动会检查target是否已经存在,如果存在且和source一致会skip。
而skip的逻辑是sameLength && sameBlockSize && checksums (这一个可以通过skipCrc=true来跳过,只检查前者,可以提升速度)。
不过这个功能实际上与文件语义是冲突的,这个后面会提到。
对于Hadoop来说,可以通过put和distcp进行文件的传输,put是把本地文件丢到分布式文件系统上,distcp是在不同的scheme之间拷贝。
他俩的逻辑类似,基本上是先产生临时文件,再rename过去,例如:
hadoop fs -put a hdfs://xx/dir |
实际的执行步骤是在hdfs://xx/dir下产生a.copy,再rename成a,对于hdfs来说,rename是个成本较低的操作,但是对于对象存储来说,这个操作成本非常高,而put和distcp各自提供了一个能力。
put可以通-d,distcp可以用-direct,例如:
hadoop distcp -direct hdfs://emr-master-1:8020/test40G tos://fcbai/hive/distcp |
这样的话,它便不会产生临时文件,也就不会有rename过程,可以大幅提高写入速度。对于distcp来说,如果不添加-direct参数,那么会直接创建临时文件,再rename:

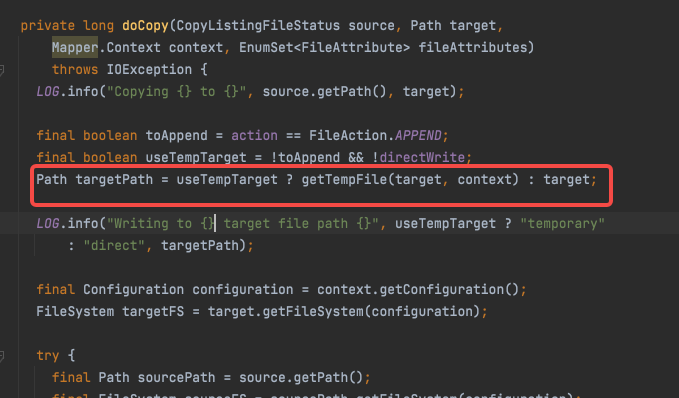
如果使用-direct 则会直接写目标地方:

所以对于distcp来说,job committer 是无效的。
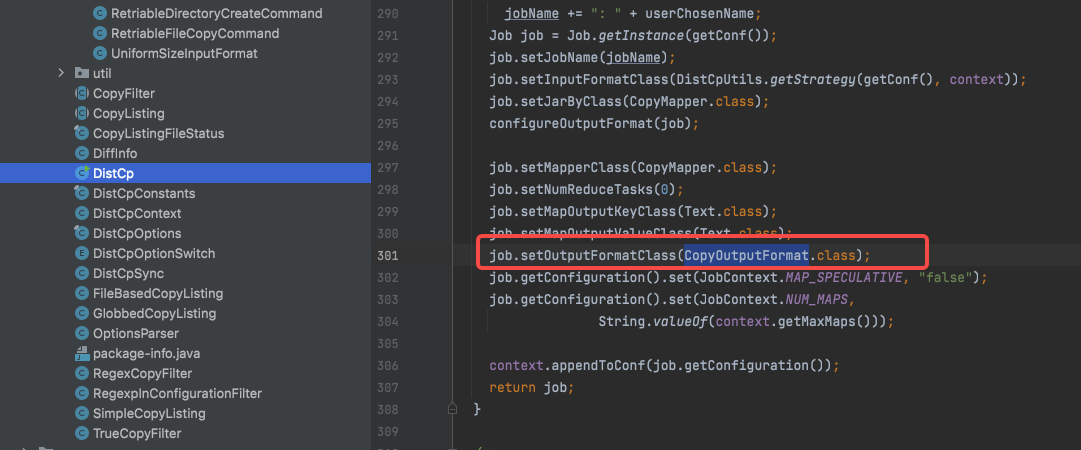
DistCp在构造Job的时候,使用的CopyOutputFormat,在new API里面committer是通过OutputFormat给创造出来的:
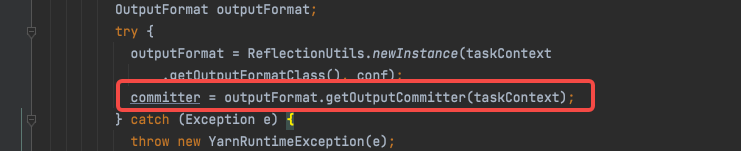
CopyOutputFormat是直接返回了FileOutput committer:

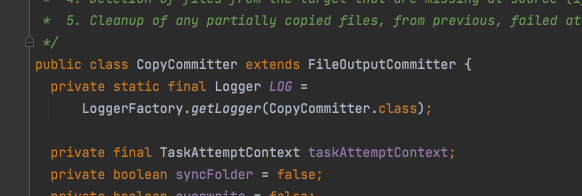
所以 没有走那个基于schema的初始化committer的逻辑,比如FileOutputFormat:
会基于不同的schema去创建不同的factory,然后创建不同的committer。
默认的这种实现,实际上是有问题的,因为无法保障原子性,比如一旦作业失败,那么会出现部分文件copy成功,而部分文件copy失败,因为hdfs的rename很短,所以这个问题的概率会变小,但是理论上会存在。
如果是对象存储,则这个问题会变大,所以应该考虑使用自己的committer去包装,解决一致性的问题,确保copy是个原子动作。
附录-MR作业基础知识
创建Mapper类
/** |
创建Reduce类
public class WCReducer extends Reducer<Text, LongWritable, Text, LongWritable> { |
创建Job
/** |
接下来打包上传执行。
扫码手机观看或分享: