Hadoop中的Secondary NameNode相关知识
启动Hadoop时,NameNode节点上会默认启动一个SecondaryNameNode进程,使用JSP命令可以查看到。SecondaryNameNode光从字面上理解,很容易让人认为是NameNode的热备服务。其实不是,SecondaryNameNode是HDFS架构中的一个组成部分。它并不是元数据节点出现问题时的备用节点,它和元数据节点负责不同的事情。
SecondaryNameNode节点的用途:
简单的说,SecondaryNameNode节点的主要功能是周期性将元数据节点的命名空间镜像文件和修改日志进行合并,以防日志文件过大。
要理解SecondaryNameNode的功能,首先我们先来了解下NameNode的主要工作:
NameNode节点的主要工作:
NameNode的主要功能之一是用来管理文件系统的命名空间,其将所有的文件和文件目录的元数据保存在一个文件系统树中。为了保证交互速度,NameNode会在内存中保存这些元数据信息,但同时也会将这些信息保存到硬盘上进行持久化存储,通常会被保存成以下文件:命名空间镜像文件(fsimage)和修改日志文件(edits)。下图是NameNode节点上的文件目录结构:
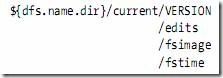
fsimage文件,也即命名空间映像文件,是内存中的元数据在硬盘上的checkpoint,它是一种序列化的格式,并不能够在硬盘上直接修改。
有了这两个文件后,Hadoop在重启时就可以根据这两个文件来进行状态恢复,fsimage相当于一个checkpoint,所以当Hadoop重启时需要两个文件:fsimage+edits,首先将最新的checkpoint的元数据信息从fsimage中加载到内存,然后逐一执行edits修改日志文件中的操作以恢复到重启之前的最终状态。
Hadoop的持久化过程是将上一次checkpoint以后最近一段时间的操作保存到修改日志文件edits中。
这里出现的一个问题是edits会随着时间增加而越来越大,导致以后重启时需要花费很长的时间来按照edits中记录的操作进行恢复。所以Hadoop用到了SecondaryNameNode,它就是用来帮助元数据节点将内存中的元数据信息checkpoint到硬盘上的。
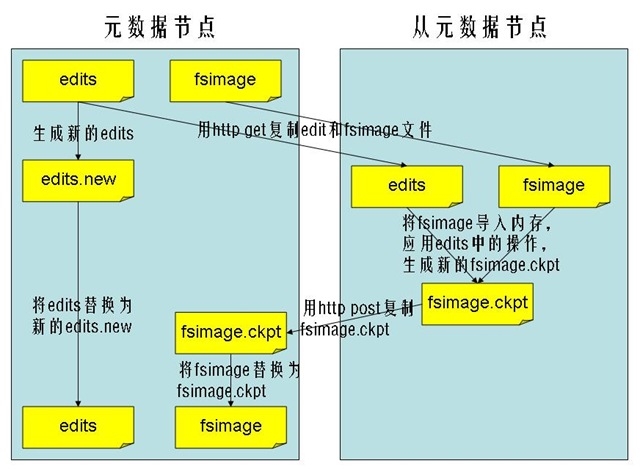
SecondaryNameNode工作流程:
- SecondaryNameNode节点通知NameNode节点生成新的日志文件,以后的日志都写到新的日志文件中。
- SecondaryNameNode节点用http get从NameNode节点获得fsimage文件及旧的日志文件。
- SecondaryNameNode节点将fsimage文件加载到内存中,并执行日志文件中的操作,然后生成新的fsimage文件。
- SecondaryNameNode节点将新的fsimage文件用http post传回NameNode节点上。
- NameNode节点可以将旧的fsimage文件及旧的日志文件,换为新的fsimage文件和新的日志文件(第一步生成的),然后更新fstime文件,写入此次checkpoint的时间。
这样NameNode节点中的fsimage文件保存了最新的checkpoint的元数据信息,日志文件也重新开始,不会变的很大了。
流程图如下所示:
SecondaryNameNode运行在另一台非NameNode的 机器上
SecondaryNameNode进程默认是运行在NameNode节点的机器上的,如果这台机器出错,宕机,对恢复HDFS文件系统是很大的灾难,更好的方式是:将SecondaryNameNode的进程配置在另外一台机器 上运行。至于为什么要将SNN进程运行在一台非NameNode的 机器上,这主要出于两点考虑:
可扩展性: 创建一个新的HDFS的snapshot需要将namenode中load到内存的metadata信息全部拷贝一遍,这样的操作需要的内存就需要 和namenode占用的内存一样,由于分配给namenode进程的内存其实是对HDFS文件系统的限制,如果分布式文件系统非常的大,那么namenode那台机器的内存就可能会被namenode进程全部占据。
容错性: 当snn创建一个checkpoint的时候,它会将checkpoint拷贝成metadata的几个拷贝。将这个操作运行到另外一台机器,还可以提供分布式文件系统的容错性。
配置将SecondaryNameNode运行在另一台机器上
HDFS的一次运行实例是通过在namenode机器上的$HADOOP_HOME/bin/start-dfs.sh( 或者start-all.sh ) 脚本来启动的。这个脚本会在运行该脚本的机器上启动 namenode进程,而slaves机器上都会启动DataNode进程,slave机器的列表保存在 conf/slaves文件中,一行一台机器。并且会在另外一台机器上启动一个SecondaryNameNode进程,这台机器由conf/masters文件指定。所以,这里需要严格注意, conf/masters 文件中指定的机器,并不是说jobtracker或者namenode进程要 运行在这台机器上,因为这些进程是运行在 launch bin/start-dfs.sh或者 bin/start-mapred.sh(start-all.sh)的机器上的。所以,masters这个文件名是非常的令人混淆的,应该叫做secondaries会比较合适。然后,通过以下步骤:
- 将所有想要运行secondarynamenode进程的机器写到masters文件中,一行一台。
- 修改在masters文件中配置了的机器上的conf/hadoop-site.xml文件,加上如下选项:
<property>
<name>dfs.http.address</name>
<value> :50070</value>
</property>
以上便是Secondary Namenode的相关知识。
扫码手机观看或分享: