反欺诈之你是否有过PS与美颜
摘要
图像欺诈的成本相对最低,从最简单的裁剪,旋转,不对等比例缩放都属于欺诈的一部分,利用类似PS等技术做出的虚假图片几乎可以达到以假乱真的效果,而目前基于深度学习的虚假图片制造则更能瞒过机器检测。相对于视频来说,视频造假的门槛则相对较高,但随着技术的普及,目前也正在走向平民化的时代,本章主要聚焦在图像方面,讲述如何进行图像反欺诈的鉴别。
目前在不同行业多少都会涉及该场景,但是从目前可用的资料,理论方面的研究,以及工程实践方面的沉淀,远没有打到稳定的状态,甚至远没打到可以实施的程度。
手工欺诈检测
对于部分企业或者职位来说,涉及到类似图片审核的时候,会有专人进行专业的识别,这类人通常拥有丰富的虚假识别经验,例如对于如下图片:

上面这张图片里的鸭子身上的光线亮度和方向明显和其他人不同,因此通过光源的情况可以发现该图片的问题,则可以断定为伪造图片,而对于另一图片来说:
这张2006年电影“美国偶像”的宣传图,几个人物眼中的高光角度不同,说明图片也是经过了处理,并非真实的图片。
可以发现对于人为检测来讲,发现图片问题,需要有人有专门的经验,这种经验更多是来自不同视角,不同思考维度的沉淀,以发现这张图片和事实或者理论不符的特征,进而推理出该图片的虚假程度。
因此对于大部分依靠人的经验鉴别的方向来说,大部分会使用如下的方法:
- 单视图测量:在图像上分别手动标出参考物体和目标物体的两个端点;求取目标物体的高度;通过判断此高度是否可信、是否在可接受的范围内来判断目标物体是否为伪造区域。
- 基于光源照射:光源直射的地方最亮,离光源越远,亮度呈梯度下降。在拿到一张照片以后,我们就可以先来看看所有的人或物体的光源特征是否全部一样。
- 反射高光:反射高光是指环境光束在眼中反射的那个小白点,而这些小白点通常可以告诉我们一些有关周围光源的信息,同类物体小白点的位置实在差太多的话,则基本为虚假图片。
- 六像素小方块对比法:以六像素小方块为基本单位,不断重叠这个动作,根据是否出现重复区域来判断是否有虚假特征,这个动作仿佛人干不了?弄个放大镜贴着眼睛不断向前滚动就好了。
对于采用人工检测来说,相对耗时比较长,并且相对的质量和效率都不高,更何况目前对于造假的效果已经达到了机器自动造假的技术,单纯通过人经验来检测,效果已经远远跟不上。
RGB识别技术
任何一个电子屏幕上看起来五彩缤纷的图片,其实每个像素点都是由红蓝绿三种颜色叠加形成的,红绿蓝,是色光的三原色。

但是,并非每个格子都储存着红黄蓝三种信号,大多数时候需要通过格子和格子之间的算法来控制颜色,所以每个格子之间其实有一定的数字关系。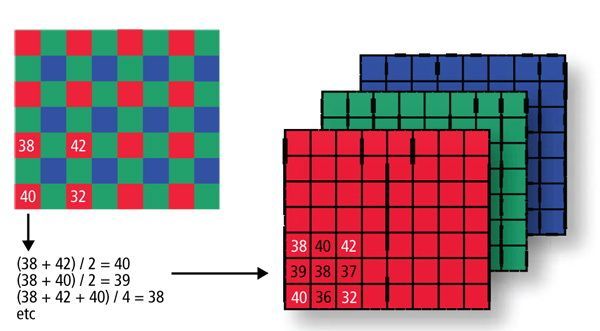
如果某一篇区域的图像跟周围没有数字关系,或者发生异常,就可以判定图片存在PS,简而言之,根据RBG颜色值的变化关系,AI系统就能迅速来检测出篡改。
基于噪点检测技术
我们使用数码相机拍照时,照片上一定会带有很多密密麻麻的小颗粒,夜间拍摄时尤其明显。
这些噪点其实也存在一些特定的分布规律,如果图片中的某个部分是复制进来的,噪点的分布以及边缘就会异常,这种异常用肉眼很难识别,用机器却可以轻易找出来。
基于双流卷积网络的检测
前面我们介绍了基于RGB识别和基于噪点检测的技术,讲两者结合在一起进行识别检测,则是目前相对效果比较好和使用比较多的方式,也就是说,我们将以上两类检测特征作为神经网络的输入,用来进行训练。
即双流卷积网络,双流CNN通过效仿人体视觉过程,对视频信息理解,在处理视频图像中的环境空间信息的基础上,对视频帧序列中的时序信息进行理解,为了更好地对这些信息进行理解,双流卷积神经网络将异常行为分类任务分为两个不同的部分。单独的视频单帧作为表述空间信息的载体,其中包含环境、视频中的物体等空间信息,称为空间信息网络;另外,光流信息作为时序信息的载体输入到另外一个卷积神经网络中,用来理解动作的动态特征,称为时间信息网络,为了获得比较好的异常行为分类效果,我们选用卷积神经网络对获得的数据样本进行特征提取和分类,我们将得到的单帧彩色图像与单帧光流图像以及叠加后的光流图像作为网络输入,分别对图像进行分类后,再对不同模型得到的结果进行融合。双流卷积神经网络结构如下图所示: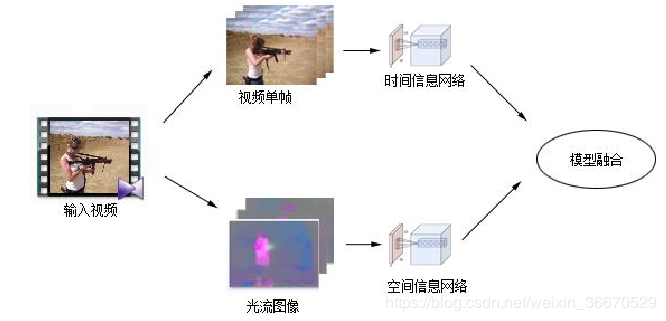
深度学习的效果好坏,很大程度上取决于网络的结构,目前深度学习的浪潮也催生了很多应用于不同任务的优秀网络结构,随着研究的深入和网络结构的加深,不同结构得出的效果也证实,随着网络层次结构的合理加深,网络的效果也有相应的提升。原始双流CNN的时空信息结构使用的是中等规模的卷积神经网络CNN_M网络结构。其网络结构如下图所示: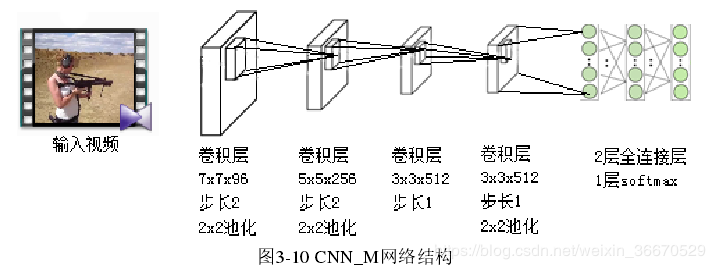
CNN_M的结构设计基本上和AlexNet是同一种思路,包括5层卷积层和3层全连接层,网络的输入图像尺寸被固定在224×224。与
AlexNet相比,CNN_M包含更多的卷积滤波器。第一层卷积层的卷积核尺寸缩小为7×7,卷积步长减小为2,其他层次的参数都与
AlexNet相同。通过增加滤波器的数量,减小滤波器的尺寸和步长,CNN_M可以更好地发现和保留原始输入图像的细节信息,因此,CNN_M学习到的滤波器较之前的网络结构有更好的鲁棒性和更高的准确率。CNN_M在ILSVRC-2014物体识别任务上获得了
13.5%的top 5错误率,较之前的网络模型有大幅度的减少。
那么双流卷积网络如何应用在图像反欺诈的场景上呢?
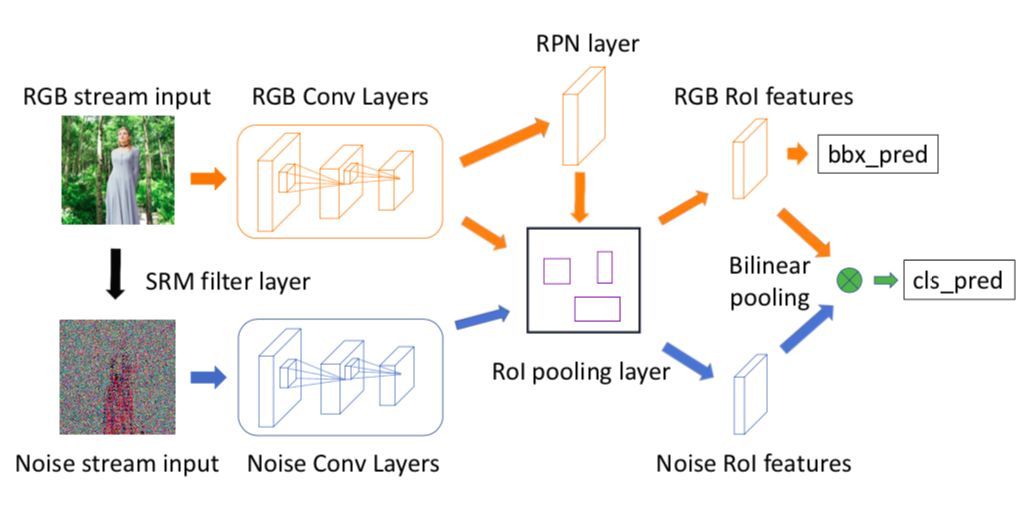
直接上网络结构,如上图结构所示,RGB通道+噪点—在CVPR 2018上公布的通道技术图。可以看出,根据通道反向追溯技术。让卷积层来快速辨别图像是否经过处理。虽然感觉起来截屏就没有通道轨迹了,但我们仔细看,是通过通道技术中的噪点来追溯的,因此即便是进行了截图操作,依旧能够发现其中的问题。

噪点+光线—通道和噪点只能辨别一部分粗糙的P图。精致的P图还是很难被认出的。在精致P图面前只有通深度学习的大量训练,通过噪点加光线会更加容易发现一些细节。有些细节会违背光学常理,显的很突兀。

当然还有些辅助手段比如:像素的平均分布比例,路径的连贯性等,最终来衡量图片是否有造假嫌疑。
目前正在整理某个项目的解决方案,当我们考虑整个图片的反欺诈操作的时候,并不是一个单纯的算法,也不是一个单纯的lib,而是一套完整的可以使用在生产环境下的端到端的解决方案,因为暂时还没有完整的解决方案的办法,思绪不清晰,暂且写篇文章捋一捋。
附录
参考资料:
论文地址:https://openaccess.thecvf.com/content_cvpr_2018/papers/Zhou_Learning_Rich_Features_CVPR_2018_paper.pdf
双流卷积神经网络实现:https://github.com/dBeker/Faster-RCNN-TensorFlow-Python3
基于双流卷积神经网络改造的图像鉴别实现:https://github.com/LarryJiang134/Image_manipulation_detection
扫码手机观看或分享: